
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- Routing Key
- @Transactional
- docker compose
- Spring Container
- securitycontextholderfilter
- 쿠버네티스
- JWT
- DLQ
- docker
- 지연 로딩
- DI
- @ComponentScan
- dockerhub
- 서블릿 컨테이너
- CORS
- MSA
- Spring Data JPA
- Web
- AWS
- JPA
- Dead Letter Queue
- JdbcTemplate
- kafka
- 스프링 부트
- mybatis
- redis
- 페이징
- Spring
- JPQL
- 컨테이너
- Today
- Total
look-forest
다양한 편의 기능 본문
- 쿼리 메소드 기능
- 메소드 이름으로 쿼리 생성
- 메소드 이름으로 JPA NamedQuery 호출 - 실무에서 거의 사용 안함(도메인에 sql 작성해야해서)
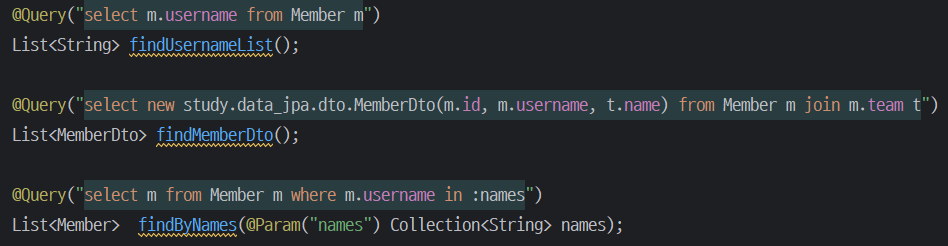
- @Query 어노테이션을 사용해서 리파지토리 인터페이스에 쿼리 직접 정의
- 벌크성 쿼리
- 엔티티 그래프 기능
메소드 이름으로 쿼리 생성
스프링 데이터 JPA는 메소드 이름을 분석해서 JPQL을 생성하고 실행한다.
//기본 생성된 메서드는 트랜잭션 처리가 되어있지만, 우리가 만든 메소드에도 트랜잭션 처리를 하려면 붙여야 한다.
@Transactional(readOnly = true)
public interface MemberRepository extends JpaRepository<Member, Long> {
List<Member> findByUsernameAndAgeGreaterThan(String username, int age);
}
쿼리 메소드 필터 조건
스프링 데이터 JPA 공식 문서 참고: (https://docs.spring.io/spring-data/jpa/docs/current/reference/ html/#jpa.query-methods.query-creation)
스프링 데이터 JPA가 제공하는 쿼리 메소드 기능
- 조회: find…By ,read…By ,query…By get…By,
예:) findHelloBy 처럼 ...에 식별하기 위한 내용(설명)이 들어가도 된다.
https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#repositories.querymethods.query-creation - COUNT: count…By 반환타입 long
- EXISTS: exists…By 반환타입 boolean
- 삭제: delete…By, remove…By 반환타입 long
- DISTINCT: findDistinct, findMemberDistinctBy
- LIMIT: findFirst3, findFirst, findTop, findTop3
https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#repositories.limitquery-result
참고로 이 기능은 엔티티의 필드명이 변경되면 인터페이스에 정의한 메서드 이름도 꼭 함께 변경해야 한다. 그렇지 않으면 애플리케이션을 시작하는 시점에 오류가 발생한다.
실무에서는 메소드 이름으로 쿼리 생성 기능은 파라미터가 증가하면 메서드 이름이 매우 지저분해진다.
그래서 아래 @Query 기능을 자주 사용하게 된다.
유연한 반환 타입 지원

@Query, 리포지토리 메소드에 쿼리 정의하기

- 실행할 메서드에 정적 쿼리를 직접 작성하므로 이름 없는 Named 쿼리라 할 수 있다.
- JPA Named 쿼리처럼 애플리케이션 실행 시점에 문법 오류를 발견할 수 있는 것이 매우 큰 장점이다.
페이징과 정렬
페이징과 정렬 파라미터
- org.springframework.data.domain.Sort : 정렬 기능
- org.springframework.data.domain.Pageable : 페이징 기능 (내부에 Sort 포함)
특별한 반환 타입
- org.springframework.data.domain.Page : 추가 count 쿼리 결과를 포함하는 페이징
- org.springframework.data.domain.Slice : 추가 count 쿼리 없이 다음 페이지 여부 확인(내부적으로 limit + 1 조회)
- List (자바 컬렉션): 추가 count 쿼리 없이 결과만 반환
Page<Member> findByUsername(String name, Pageable pageable); //count 쿼리 사용
Slice<Member> findByUsername(String name, Pageable pageable); //count 쿼리 사용 안함
List<Member> findByUsername(String name, Pageable pageable); //count 쿼리 사용 안함
List<Member> findByUsername(String name, Sort sort);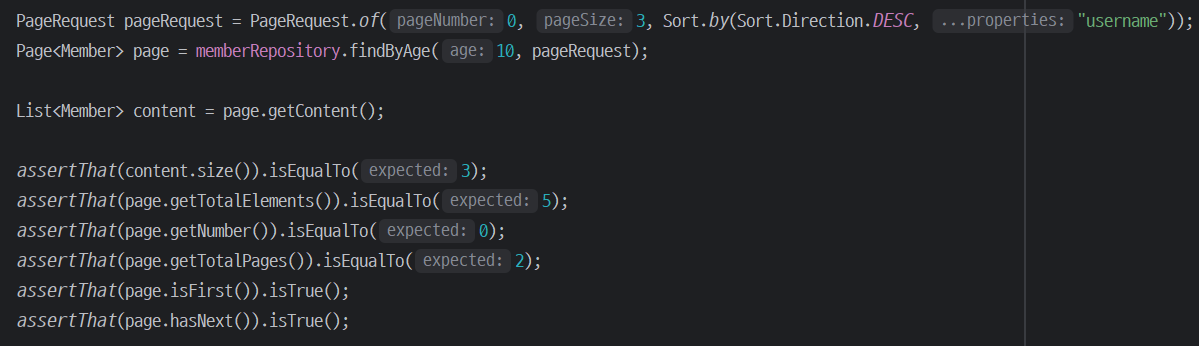
public interface Page<T> extends Slice<T> {
int getTotalPages(); //전체 페이지 수
long getTotalElements(); //전체 데이터 수
<U> Page<U> map(Function<? super T, ? extends U> converter); //변환기
}public interface Slice<T> extends Streamable<T> {
int getNumber(); //현재 페이지
int getSize(); //페이지 크기
int getNumberOfElements(); //현재 페이지에 나올 데이터 수
List<T> getContent(); //조회된 데이터
boolean hasContent(); //조회된 데이터 존재 여부
Sort getSort(); //정렬 정보
boolean isFirst(); //현재 페이지가 첫 페이지 인지 여부
boolean isLast(); //현재 페이지가 마지막 페이지 인지 여부
boolean hasNext(); //다음 페이지 여부
boolean hasPrevious(); //이전 페이지 여부
Pageable getPageable(); //페이지 요청 정보
Pageable nextPageable(); //다음 페이지 객체
Pageable previousPageable();//이전 페이지 객체
<U> Slice<U> map(Function<? super T, ? extends U> converter); //변환기
}
카운트 쿼리 분리
전체 count 쿼리는 매우 무겁다.
따라서 left join 등을 사용한 복잡한 sql에서는 가능한 카운트 쿼리를 분리하는 것이 좋다.
(예를 들어 데이터는 left join, 카운트는 left join 안해도 됨. 총 데이터 수는 같은 경우이므로)
@Query(value = "select m from Member m left join m.team t",
countQuery = "select count(m.username) from Member m")
Page<Member> findMemberAllCountBy(Pageable pageable);(아래에 나오는 쿼리 힌트를 사용할 수도 있다)
페이지를 유지하면서 엔티티를 DTO로 변환하기
API 사용 시 엔티티를 그대로 반환해선 안된다. DTO로 변환해서 반환하려면 다음과 같이 사용하자.
Page<Member> page = memberRepository.findByAge(10, pageRequest);
Page<MemberDto> dtoPage = page.map(m -> new MemberDto(m));
벌크성 수정 쿼리
벌크성 수정, 삭제 쿼리는 @Modifying 어노테이션을 사용해야 한다. (사용하지 않으면 getSingleResult 등으로 인식)
벌크성 쿼리를 실행 시 영속성 컨텍스트 무시하므로 실행 후 영속성 컨텍스트 초기화해야 한다.
1. 영속성 컨텍스트에 엔티티가 없는 상태에서 벌크 연산을 먼저 실행한다.
2. 부득이하게 영속성 컨텍스트에 엔티티가 있으면 벌크 연산 직후 영속성 컨텍스트를 초기화 한다.

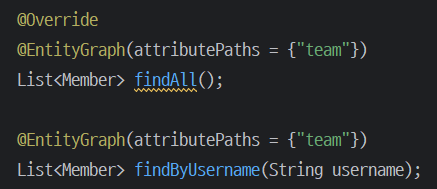
@EntityGraph
연관된 엔티티들을 SQL 한번에 조회하는 방법.
연관된 엔티티를 한번에 조회하려면 페치 조인이 필요하다.

위와 같이 fetch join을 사용해도 되지만,
스프링 데이터 JPA는 JPA가 제공하는 엔티티 그래프 기능을 편리하게 사용하게 도와준다.
간단한 경우엔 @EntityGraph를 사용하면 된다.
@NamedEntityGraph
@NamedEntityGraph는 이 Entity Graph를 미리 정의하여 재사용 가능하게 만들어 준다.
애그리게이트 단위로 레포지토리를 설정할 때 유용하다.
@Entity
@NamedEntityGraphs(
@NamedEntityGraph(
name="Movie.policy",
attributeNodes = {
@NamedAttributeNode(
value = "discountPolicy",
subgraph = "policy.conditions")
},
subgraphs = {
@NamedSubgraph(
name = "policy.conditions",
attributeNodes = @NamedAttributeNode("conditions"))
}
)
)
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Movie {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
@OneToOne(cascade = CascadeType.ALL, orphanRemoval = true)
@JoinColumn(name="POLICY_ID")
private DiscountPolicy discountPolicy;
...
}subgraphs : 연관된 엔티티 내의 또 다른 속성을 정의할 때 사용 (선택사항)
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name="policy_type")
@NoArgsConstructor @Getter
public abstract class DiscountPolicy {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@OneToMany(cascade = CascadeType.ALL, orphanRemoval = true, fetch = FetchType.LAZY)
@JoinColumn(name = "POLICY_ID")
private Set<DiscountCondition> conditions = new HashSet<>();
...
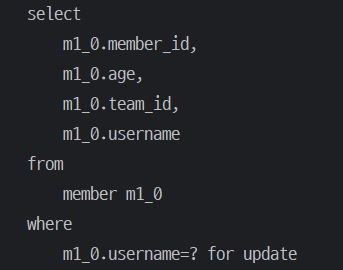
}public interface MovieRepository extends JpaRepository<Movie, Long> {
@EntityGraph(value = "Movie.policy")
@Query("select m from Movie m where m.id = :id")
Optional<Movie> findAggregateById(Long id);
}
# 생성된 쿼리
select
m1_0.id,
dp1_0.id,
dp1_0.policy_type,
c1_0.policy_id,
c1_0.id,
c1_0.condition_type,
m1_0.title,
from
movie m1_0
left join
discount_policy dp1_0
on dp1_0.id=m1_0.policy_id
left join
discount_condition c1_0
on dp1_0.id=c1_0.policy_id
where
m1_0.id=?JPA Hint & Lock
JPA Hint
@QueryHints 애노테이션을 사용해서 JPA 구현체에 쿼리 힌트를 줄 수 있다.
가령, Dirty check를 하는 경우 영속성 컨텍스트에 스냅샵을 남겨 flush 전에 비교한다.
그런데 단순히 조회만 할 목적이라면 JPA 구현체에게 힌트를 줘서 스냅샷을 남기지 않을 수 있다. (dirty check X)

페이징 처리 시 사용하는 정도.

Lock
@Lock 애노테이션을 사용하면 select 문에도 lock을 걸 수 있다.
트래픽이 적으면서 돈 계산 등 락이 반드시 필요한 경우에만 사용을 고려하자.

참고 자료 & 이미지 출처
실전! 스프링 데이터 JPA (김영한 님)
'JPA > Spring data JPA' 카테고리의 다른 글
| 스프링 데이터 JPA 분석 (0) | 2024.10.20 |
|---|---|
| 확장 기능 (2) | 2024.10.20 |
| 공통 인터페이스 기능 (0) | 2024.10.19 |


