
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- mybatis
- docker
- redis
- 컨테이너
- Spring
- Spring Data JPA
- dockerhub
- MSA
- Routing Key
- Web
- JWT
- DLQ
- 페이징
- Spring Container
- docker compose
- @ComponentScan
- Dead Letter Queue
- 스프링 부트
- securitycontextholderfilter
- AWS
- 쿠버네티스
- JPQL
- kafka
- JdbcTemplate
- @Transactional
- 지연 로딩
- CORS
- DI
- 서블릿 컨테이너
- JPA
- Today
- Total
look-forest
대용량 데이터의 조회(feat.페이징,인덱스) 본문
게시글 CRUD API를 만들고, 대용량 데이터를 조회하는 상황을 가정하자.
테이블 구조는 다음과 같다.
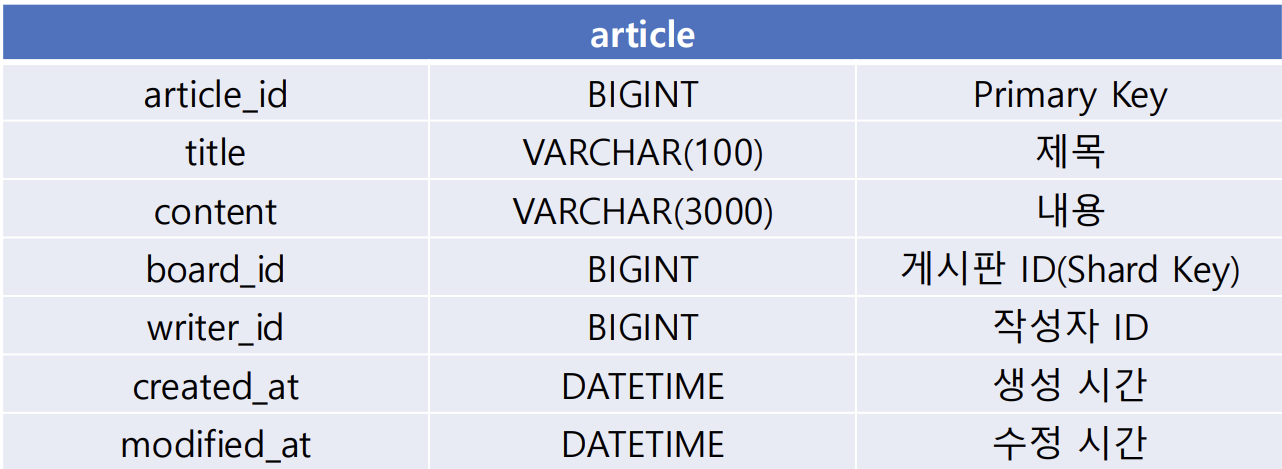
분산 데이터베이스를 가정하기 때문에 게시글이 N개의 샤드로 분산되는 상황을 고려한다.
- Shard Key = board_id (게시판 단위로 게시글 목록을 조회하므로)
- Hash-based Sharding이라고 가정
Primary Key는 오름차순 유니크 숫자를 애플리케이션에서 직접 생성한다. (Snowflake, TSID 등)
페이징
대규모 데이터에서 게시글 목록 조회는 왜 복잡할까?
모든 데이터를 한 번에 보여줄 수 없다. (메모리, 네트워크, 성능 상 제약)
=> 페이징 필요
페이징 처리를 하려면?
디스크에 저장된 모든 데이터를 메모리로 가져오고, 특정 페이지만 추출하는 것은 비효율적
- 디스크 I/O 비용
- 메모리 용량 초과 -> OOM
=> 따라서 DB에서 특정 페이지의 데이터만 추출하는 페이징 쿼리가 필요하다.
페이징 방식
페이징 방식은 클라이언트 또는 서비스 특성에 따라서 크게 두 가지로 나뉜다.
- 페이지 번호: 이동한 페이지 번호가 명시적으로 지정, 원하는 페이지로 즉시 이동 가능
- 무한 스크롤: 스크롤을 내리면 다음 데이터 조회, 주로 모바일 환경에서 사용
페이지 번호 방식
페이지 번호 방식에서는 다음 두가지 정보가 필요하다.
- N번 페이지에서 M개의 게시글
- 게시글의 개수
1. N번 페이지에서 M개의 게시글(페이징 쿼리)
N번 페이지에서 M개의 게시글을 조회하려면?
offset, limit을 활용하여, offset 지점으로부터 limit개의 데이터를 조회한다.
- offset = (N번 페이지 -1) *M
- limit = M
select *
from article
where board_id = {board_id} // 게시판별 (단일 샤드에서 조회)
order by created_at desc // 최신순
limit {limit} offset {offset}; // N번 페이지에서 M개
1번 게시판, 4번 페이지에서 30건의 데이터를 조회해보자.
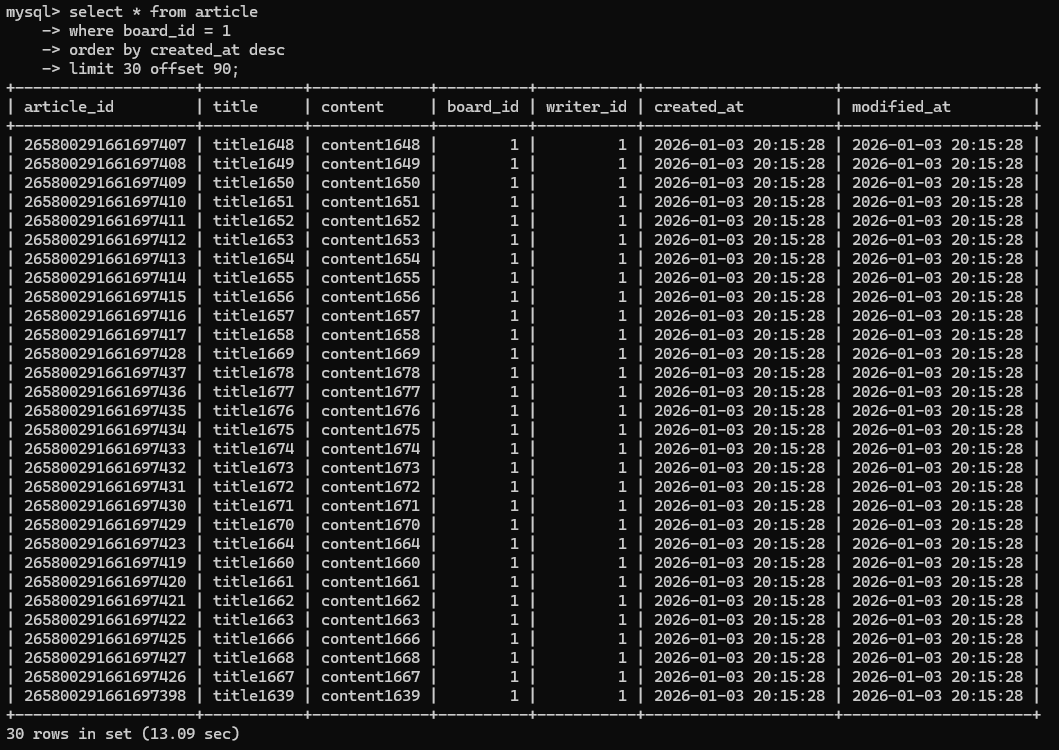
고작 1,200만 건의 데이터에서 30개의 게시글을 조회하는데 13초가 걸렸다. 정상 서비스가 어려운 상황이다.
이유가 뭘까? explain 명령어를 사용하여 Query Plan을 확인해보자.

type = ALL : 테이블 전체를 읽는다. (풀 스캔)
Extras = Using where: where 절로 조건에 대해 필터링
Using filesort: 데이터가 많기 때문에 메모리에서 정렬을 수행할 수 없어서, 파일(디스크)에서 데이터를 정렬 수행
=> 전체 데이터에 필터링 및 정렬하기 때문에 아주 큰 비용이 든 것이다.
이러한 문제를 해결하려면 인덱스를 사용해야 한다.
※ 인덱스
인덱스는 데이터를 빠르게 찾기 위한 방법이다.
인덱스 관리를 위해 부가적인 쓰기 작업과 공간이 필요한데, 왜 쓸까? 왜 인덱스를 쓰면 빠를까?
- 다양한 데이터 특성과 쿼리를 지원하는 다양한 자료구조(B+tree, Hash, bitmap,,)를 활용
- Relational Database에서는 주로 B+tree(Balanced Tree)가 사용됨
- 쓰기 시점에 B+tree 구조의 정렬된 상태의 데이터가 생성됨
=> 이미 인덱스로 지정된 컬럼에 대해 정렬된 상태를 가지고 있으므로,
조회 시점에 전체 데이터를 정렬하고 필터링할 필요가 없음 (조회 쿼리가 빠름) - 검색, 삽입, 삭제 연산을 로그 시간에 수행 가능
- 트리 구조에서 leaf node 간 연결되기 때문에 범위 검색에 효율적
- 쓰기 시점에 B+tree 구조의 정렬된 상태의 데이터가 생성됨

인덱스 생성
게시판 별 최신 순 조회를 위한 인덱스를 만들고, 쿼리 튜닝 후 성능을 테스트해보자.
//24초에 걸려 수행되었다.
create index idx_board_id_article_id on article(board_id asc, article_id desc);
이로써 조회 시점에 데이터를 정렬하고, 모든 데이터에 대해 직접 필터링하는 과정이 사라졌다.
인덱스는 순서가 중요하다.
게시판별 최신 순 조회를 할 것이므로, 생성 시간의 역순으로 정렬해야 한다.
그런데 왜 created_at이 아니라 article_id를 사용할까?
대규모 트래픽을 처리하기 위한 분산 환경에서는, 게시글 서비스의 각 애플리케이션이 여러 서버로 분산되어 동시 처리될 수 있다.
즉, 게시글이 동시에 생성될 수 있으므로 created_at이 중복될 수 있다.
따라서 created_at을 정렬 조건으로 사용하면, 동일 시간일 경우 순서가 명확하지 않다.
그렇게 되면 조회 결과가 달라질 수 있고, 페이징 시 데이터 중복 및 누락 가능성이 생긴다.
article_id는 분산 시스템에서 고유한 오름차순을 위해 고안된 알고리즘(snowflake)를 사용하므로 중복 가능성이 현저히 작으며,
생성 시간에 의해 정렬된 상태를 가지고 있다. 따라서 article_id를 최신순 정렬 용으로 사용할 수 있다.
쿼리 튜닝
생성된 인덱스를 쿼리에 사용할 수 있어야 한다.
이에 따라 쿼리의 order by를 created_at에서 article_id로 튜닝하자.
select *
from article
where board_id = {board_id}
order by article_id desc
limit {limit} offset {offset};
조회 해보면 13초 걸리던 쿼리가 0초대에 수행되었다!

쿼리 플랜을 살펴보면, 생성한 인덱스가 쿼리에 사용됐음을 확인할 수 있다.

한계
이로써 모든 문제가 해결되었을까?
이번에는 50,000 페이지를 조회해보자.
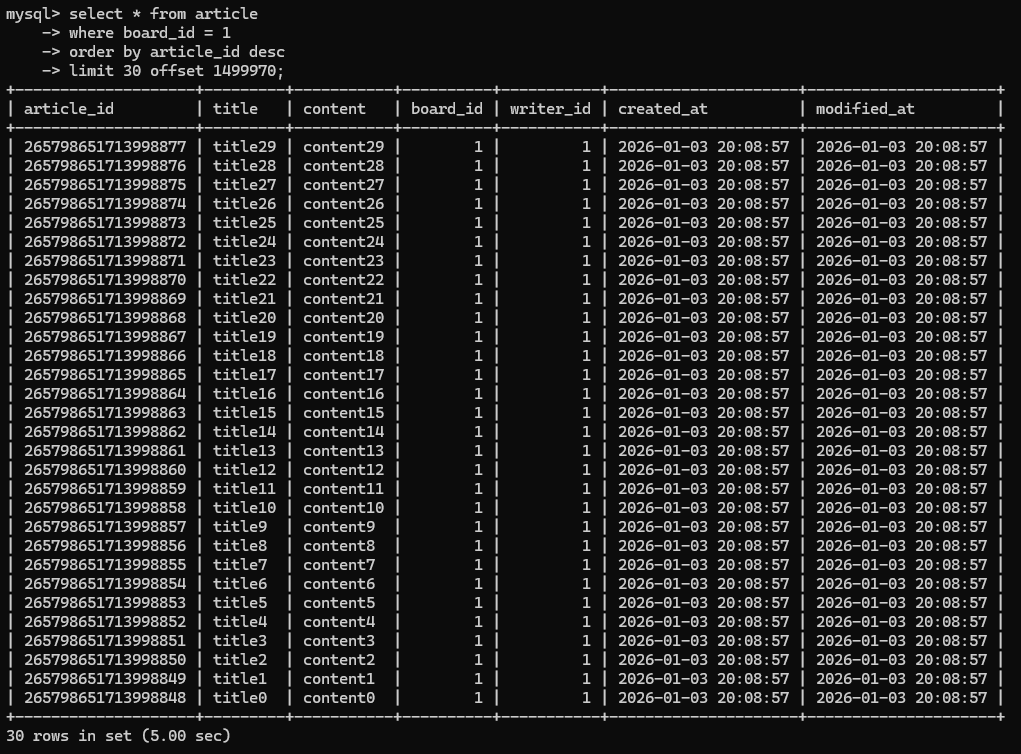
이번에는 약 5초가 사용되었다.. 쿼리플랜을 보면 인덱스를 사용하긴 했다.
뒷 페이지로 갈수록 성능이 느려진 이유가 뭘까?
이를 이해하기 위해서는 인덱스의 종류를 알아야 한다.
인덱스의 종류
1. Clustered Index (Primary Index)
2. Secondary Index (Non-clustered Index)

MySQL의 기본 Storage Engine(데이터 저장 및 관리 장치)인 InnoDB는
테이블마다 Clustered Index를 자동 생성하는데, Primary Key 기준으로 정렬되어 있다.
그리고 Clustered Index는 leaf node의 값으로 행 데이터를 가진다.

Primary Key를 이용한 조회는, 자동으로 생성된 Clustered Index로 수행된다.

우리가 생성한 인덱스는 Secondary Index이다.
Secondary Index의 leaf node는 다음 데이터를 가지고 있다.
- 인덱스 컬럼 데이터
- 데이터에 접근하기 위한 포인터
- 데이터는 Clustered Index가 가지고 있다.
=> 따라서 Clustered Index의 데이터에 접근하기 위한 포인터는 Primary Key이다.
- 데이터는 Clustered Index가 가지고 있다.
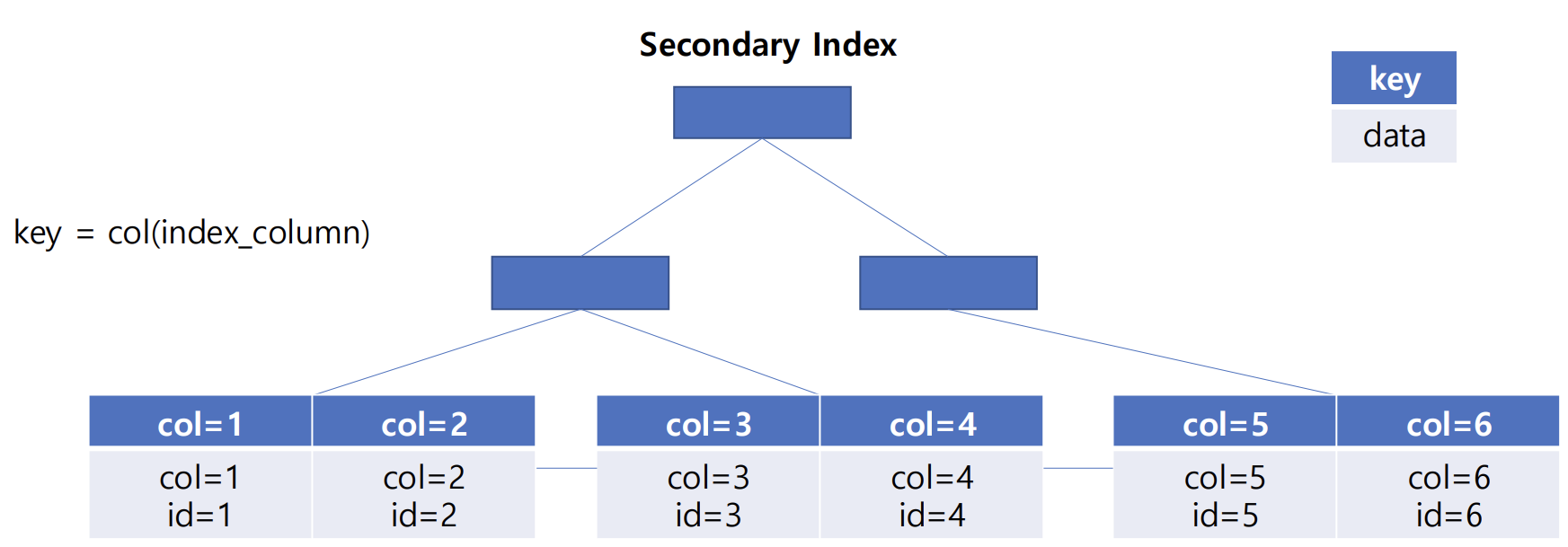
우리가 만든 인덱스는 다음과 같은 구조를 갖고 있다.
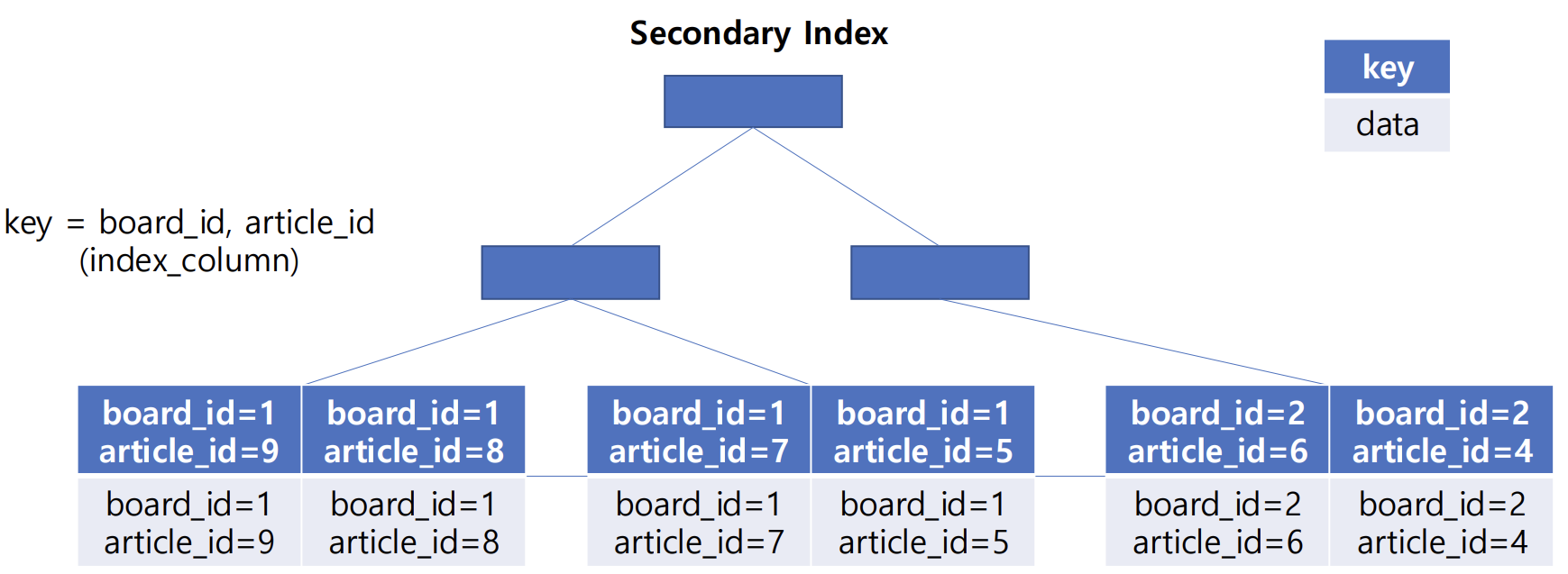
Secondary Index를 통해 데이터가 조회되는 과정
그렇다면 Secondary Index를 이용한 조회는 어떻게 처리되는가?
- Secondary Index는 데이터에 접근하기 위한 포인터만 가지고 있다.
- 그리고 데이터는 Clustered Index가 가지고 있다
Secondary Index를 이용한 데이터 조회는 인덱스를 두 번 탄다.
- Secondary Index에서 데이터에 접근하기 위한 포인터를 찾은 뒤,
- Clustered Index에서 데이터를 찾는다.

이러한 개념을 바탕으로, 우리의 페이징 쿼리를 다시 살펴보자.
select *
from article
where board_id = 1
order by article_id desc
limit 30 offset 1499970;
- (board_id, article_id)에 생성된 Secondary Index에서 article_id를 찾는다.
- Clustered Index에서 article 데이터를 찾는다.
- offset 1499970을 만날 때까지 반복하며 skip 한다.
- limit 30개를 추출한다.
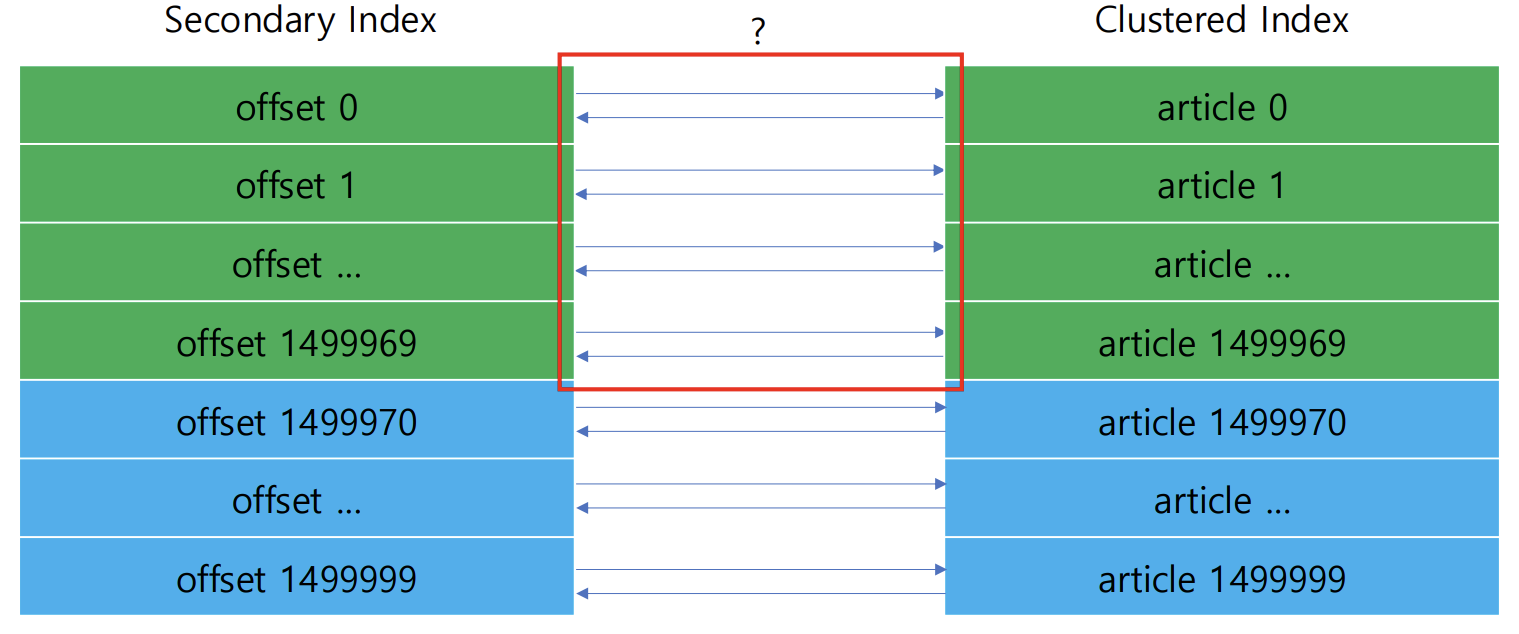
데이터는 offset 1499970부터 30개만 필요하다. 그런데 offset 1499970을 만날 때 까지 데이터에 접근하고 있는 것이다.
이렇게 비효율적이고 무의미한 과정을 생략할 수는 없을까?
Covering Index
article_id는 Clustered Index에 접근하지 않아도 가져올 수 있는 정보이다.
Secondary Index에서 필요한 30건에 대해서 article_id만 먼저 추출하고, 그 30건에 대해서만 Clustered Index에 접근하면 충분하지 않을까?
확인을 위해 secondary index에서 가져올 수 있는 정보인 board_id와 article_id만 조회하도록 쿼리를 바꾸고 수행해보자.

쿼리 플랜을 확인해보면, 인덱스는 동일하게 사용되었는데, Extra = Using index가 추가되었다.
인덱스만 사용해서 데이터를 조회했음을 의미한다.

이렇게 인덱스의 데이터만으로 조회를 수행할 수 있는 인덱스를 Covering index라고 한다.
- 인덱스만으로 쿼리의 모든 데이터를 처리할 수 있는 인덱스 (테이블 접근 없음)
- 데이터(Clustered Index)를 읽지 않고, 인덱스(Secondary Index) 포함된 정보만으로 쿼리 가능한 인덱스
(조회 컬럼이 인덱스에 모두 포함)
| Extra 값 | 의미 | Covering Index 여부 |
| Using index | 인덱스만 읽음 | ✅ 맞음 |
| Using where; Using index | 인덱스만 읽고 필터링 | ✅ 맞음 |
| Using index condition | 인덱스 + 테이블 접근 | ❌ 아님 |
| Using where | 테이블 접근 | ❌ 아님 |
Covering Index를 활용하여, Primary Index에 불필요하게 접근하지 않으면 문제가 해결된다!
select *
from (
select article_id
from article
where board_id = 1
order by article_id desc
limit 30 offset 1499970
) t left join article
on t.article_id = article.article_id;
쿼리플랜을 살펴보면,

sub query 과정에서 파생 테이블이 생기지만(Derived), 커버링 인덱스가 사용되었기 때문에(Using index)
join한 30건에 대해서만 Clustered Index를 타서 빠르게 처리될 수 있었다.
인덱스의 한계와 다른 해결법
쿼리를 튜닝한 덕분에 50,000번 페이지를 조회하더라도 빠르게 처리된다.
그런게 300,000번 페이지를 조회하면 어떻게 될까?
약 2초정도 소요되는데, 뒷 페이지로 갈수록 속도가 느려지는 문제는 여전한 것이다.
secondary index만 탄다고 하더라도, offset만큼 Index scan이 필요하니까 늘어날수록 느려질 수 밖에 없는 것이다.
이를 해결하기 위해서는 여러 방법이 있을 수 있는데,
- 데이터를 한 번 더 분리한다.
가령 게시글을 1년 단위로 테이블 분리할 수 있다. 개별 테이블 크기를 작게 만드는 것이다. - offset skip 단위를 늘린다.
조회할 offset이 1년 동안 작성된 게시글 수보다 크다면, 1년 동안 작성된 게시글 수 단위로 즉시 skip하도록 코드를 짠다. - 정책으로 풀어내기.
게시글 조회는 10,000번 페이지까지로 제한(300,000 페이지를 조회하는게 정상적인 사용자일까?) - 시간 범위 또는 텍스트 검색 기능 제공
더 작은 데이터 집한 내에서 페이징을 수행한다.
2. 게시글의 개수
게시글 개수를 count하는 이유
게시글의 개수는, 데이터 유무에 따라서 몇 페이지까지 활성화할지 결정하기 위해 필요하다.

페이지 당 30개의 게시글을 페이지 이동 버튼 10개씩 노출한다면,
- 게시글이 50개 있다면 2페이지까지 활성화
- 게시글이 301개 이상 있다면 다음페이지까지 활성화(11페이지가 있음을 의미)
전체 게시글의 수를 확인하면 느리다!
게시판별 게시글 개수 쿼리를 수행해보자.
select count(*) from article where board_id = 1
개수만 카운트하면 되므로 커버링 인덱스로 동작하나, 게시판의 모든 게시글 수를 확인해야 하므로 실행 시간이 길다.
데이터 양이 많을 수록 더욱 느려질 것이다.
그런데, 이동 가능한 페이지 번호 활성화를 위함이라면, 모든 게시글의 개수가 필요하진 않다.
사용자가 현재 이용 중인 페이지 기준에 따라서, 게시글 개수의 일부만 확인하면 되는 것이다.
- 사용자가 1~10번 페이지에 있을 때에는, 1~10번 페이지와 다음 버튼만 활성화
- 사용자가 11~20번 페이지에 있을 때에는, 11~20번 페이지와 이전/다음 버튼만 활성화
- 사용자가 21~30번 페이지에 있을 때에는, 21~30번 페이지와 이전/다음 버튼만 활성화
- 901개면 다음 버튼까지 활성화
- 901개 미만이면 개수만큼 페이지 버튼 활성
가령 사용자가 10,001~10,010번 페이지에 있다면, 모든 게시글 수를 카운트하지 않고 300,301개까지만 카운트해 볼 수 있다.
전체가 아니라 일부에 대해서만 카운트할 수 있으므로, 큰 비용 없이 처리될 수 있다.
공식화해보면 다음과 같다.
(((n – 1) / k) + 1) * m * k + 1
- 현재 페이지(n)
- 페이지 당 게시글 개수(m)
- 이동 가능한 페이지 개수(k)
따라서 count 쿼리를 일부만 조회하도록 만들면 된다.
※ count 쿼리에서 limit은 동작하지 않고 전체 개수를 반환하므로 sub query에서 limit만큼 조회하고 count. 정렬은 필요없다.
select count(*)
from (
select article_id
from article
where board_id = {board_id}
limit {limit}
) t;
※ 물론 게시글 개수를 데이터로 미리 만들어 놓을 수 있다.(생성/삭제 시점마다 업데이트)
하지만 동시 요청 발생 시 데이터가 부정확해질 수 있는데, 이를 해결하는 방법은 추후 알아본다.
구현
Pageable을 쓰면 위에서 말한 최적화가 안된다!
Native Query를 쓰자.

무한 스크롤 방식
조회 방식
주로 모바일 환경에서 사용되는 방식으로, 스크롤을 내리면 다음 데이터가 조회된다.
페이지 번호 방식을 사용하면, 데이터 조회 시점에 데이터가 신규 추가/삭제되었을 경우 조회 데이터가 중복/누락될 수 있는 문제가 있는데, 무한 스크롤에는 조회 방식의 특성 상 더 적합한 방법이 있다.
바로, 마지막으로 불러온 데이터를 기준점으로 활용하는 것이다.
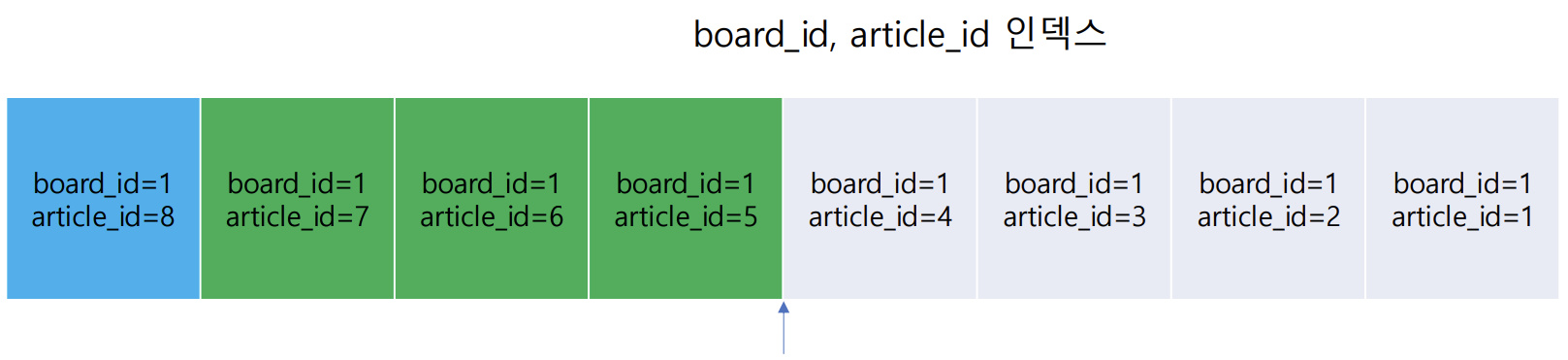
사용자는 스크롤을 내려서 두번째 스크롤을 조회할 때, 기준점 미만의 데이터를 조회한다.
정확한 데이터 기준점이 있기 때문에, 인덱스에서 로그 시간에 기준점을 찾을 수 있다.
즉, offset만큼 scan하는 과정이 필요없으므로, 뒷 페이지로 가도 균등한 속도를 보장할 수 있다!
구현
이러한 방식으로, 무한 스크롤에 적합한 페이징을 만들 수 있다.
- 첫 페이지를 조회한 Client는 마지막 조회한 데이터의 기준점을 알고 있다.
- 다음 페이지를 불러올 때, 마지막 조회한 데이터의 기준점을 파라미터로 전달
- DB는 기준점으로 쿼리 수행(기준점에 생성된 인덱스를 통해 로그 시간에 접근)
//1번 페이지
select * from article
where board_id = {board_id}
order by article_id desc limit 30;
//2번 페이지 이상. 기준점 = {last_article_id}
select * from article
where board_id = {board_id}
and article_id < {last_article_id}
order by article_id desc limit 30;

참고 자료 & 이미지 출처
스프링부트로 직접 만들면서 배우는 대규모 시스템 설계 - 게시판
'Architecture > 대규모 시스템 설계' 카테고리의 다른 글
| 동시성 문제 (feat.좋아요 수) (0) | 2026.02.08 |
|---|---|
| 계층형 구조와 페이징(feat.댓글) (0) | 2026.01.23 |
| Primary key 생성 전략 (0) | 2026.01.03 |
| Distributed Database (0) | 2026.01.02 |
| 프로젝트 셋팅 (0) | 2026.01.02 |