
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- Spring Data JPA
- 쿠버네티스
- 컨테이너
- docker compose
- @Transactional
- Spring Container
- Spring
- AWS
- DI
- redis
- MSA
- mybatis
- Dead Letter Queue
- DLQ
- JPQL
- dockerhub
- securitycontextholderfilter
- CORS
- docker
- @ComponentScan
- 페이징
- Web
- 서블릿 컨테이너
- JdbcTemplate
- JWT
- kafka
- 지연 로딩
- 스프링 부트
- Routing Key
- JPA
- Today
- Total
look-forest
Kafka 장애 대비하기 (고가용성) 본문
kafka의 고가용성(시스템이 장애 상황에서도 멈추지 않고 정상적으로 서비스를 제공할 수 있는 능력)을 확보하는 방법을 이해하려면 아래 용어들을 먼저 알고있어야 한다.
노드, 브로커, 컨트롤러, 클러스터, 레플리케이션
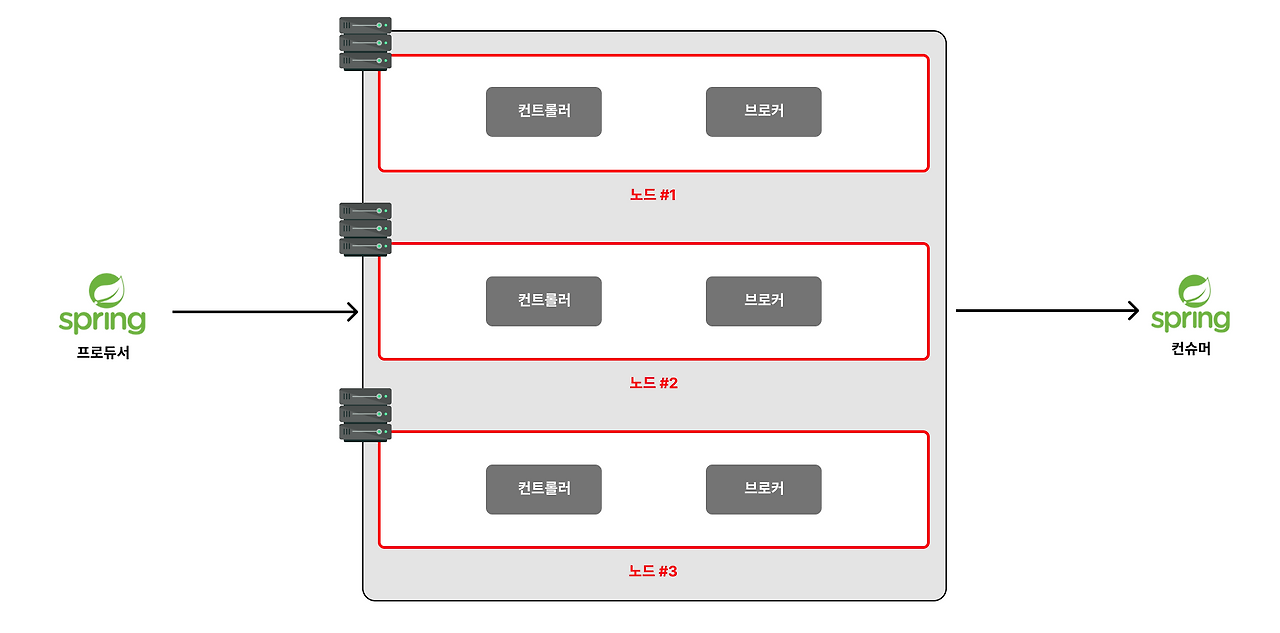
노드(node)와 클러스터(cluster)란?
Node는 서버 1대라는 의미이고, Cluster는 여러 대의 서버가 연결되어 하나의 시스템처럼 동작하는 서버들의 집합이라는 뜻으로 널리 쓰인다. kafka에서 Node는 카프카가 설치되어 있는 서버를 의미하고, 클러스터는 노드들의 묶음이다.

노드(node)가 고장나게 되면 메시지를 전달하는 것 자체가 막히기 때문에, 서비스 장애가 일어나게 된다. 그래서 실무에서는 최소 3대의 노드(node)를 구성한다.
3대의 노드로 클러스터를 구성하면, 3대의 노드들이 서로 유기적으로 작동한다. 서로 들어오는 메시지를 나눠 저장하고, 서로의 복제본을 생성해 유지할 수도 있으며, 장애 시 시스템 전체가 중단없이 작동되게 만든다.
브로커(broker), 컨트롤러(controller)란?
kafka 서버는 크게 컨트롤러(controller)와 브로커(broker)로 구성되어 있다.
브로커(broker)란, 메시지를 저장하고 클라이언트의 요청을 처리하는 역할을 한다. (직원)
컨트롤러(controller)란, 브로커들간의 연동과 전반적인 클러스터의 상태를 총괄한다. (총관리자)
기본적으로 kafka 노드에서 broker는 9092번 포트에서 실행되고, controller는 9093번 포트에서 별개의 프로세스로 실행된다.
레플리케이션(replication)이란?
kafka에서의 replication은, 데이터의 안정성과 가용성을 높이기 위해 토픽의 파티션을 여러 노드에 복제하는 걸 의미한다.
레플리케이션 개수는 kafka 서버 수만큼 설정할 수 있지만, 실무에서는 레플리케이션 개수를 2나 3으로 설정해서 활용하는 편이다.
(한 클러스터의 노드가 7개여도 레플리케이션 개수는 2-3대 정도이다)

복제된 파티션들은 리더 파티션(원본)과 팔로워 파티션(복제본)으로 구분된다.
- 리더 파티션은 프로듀서나 컨슈머가 직접적으로 메시지를 쓰고 읽는 파티션이다.
반면 팔로워 파티션은 프로듀서나 컨슈머가 직접적으로 메시지를 쓰고 읽지 않는다. - 팔로워 파티션은 리더 파티션의 메시지를 실시간으로 복제하며 유지한다.
- 리더 파티션에 장애가 발생하면 팔로워 파티션이 리더 역할로 승격한다.
이미 팔로워 파티션은 리더 파티션 내부의 메시지까지 복제해서 가지고 있으므로 정상적으로 이어서 처리할 수 있다.
실습
3대의 노드로 클러스터 구성하기
현업의 구성처럼 구축하려면 각각의 EC2 인스턴스에 kafka 노드를 따로따로 설치해야 하지만, 비용 절감과 실습의 편의를 위해 하나의 EC2 인스턴스에 3개의 kafka 노드를 한꺼번에 셋팅할 것이다.
1. Kafka 설정 수정하기
server.propertie를 수정하고, server2.properties, server3.properties로 복제하여 설정을 수정해준다.
2번 서버의 포트는 19092, 19093, 3번 서버는 29092, 29093으로 설정한다.
...
# kafka 노드를 식별하는 ID
node.id=1
# 클러스터를 구성할 컨트롤러의 노드 주소 목록을 설정
# (추가적인 노드의 컨트롤러를 19093, 29093번 포트에 실행시킬 예정)
controller.quorum.bootstrap.servers={EC2 Public IP}:9093,{EC2 Public IP}:19093,{EC2 Public IP}:29093
# 브로커, 컨트롤러 프로세스를 실행시킬 포트를 지정
# (브로커를 PLAINTEXT, 컨트롤러를 CONTROLLER라고 지칭)
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
# 외부에서 접근할 수 있는 주소
advertised.listeners=PLAINTEXT://{EC2 Public IP}:9092,CONTROLLER://{EC2 Public IP}:9093
# kafka가 데이터(kafka 설정, 브로커가 받은 메시지, 로그 등)를 저장할 디렉터리 경로 설정
log.dirs=/tmp/kafka-logs-1
...
2. 첫 노드는 클러스터를 초기화하고, 나머지 노드는 해당 클러스터에 연결하기
cd .. # kafka 디렉터리로 이동
# kafka 종료하기
$ bin/kafka-server-stop.sh
# 처음 실행하는 kafka 노드는 아래 명령어로 실행
$ KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
$ KAFKA_CONTROLLER_ID="$(bin/kafka-storage.sh random-uuid)"
$ bin/kafka-storage.sh format \
-t $KAFKA_CLUSTER_ID \
-c config/server.properties \
--initial-controllers "1@localhost:9093:$KAFKA_CONTROLLER_ID"
# 추가로 연동시킬 kafka 노드는 아래 명령어로 실행
# 주의 : server.properties가 아니라 server2.properties를 사용해야 한다.
$ bin/kafka-storage.sh format \
-t $KAFKA_CLUSTER_ID \
-c config/server2.properties \
--no-initial-controllers
# 추가로 연동시킬 kafka 노드는 아래 명령어로 실행
# 주의 : server.properties가 아니라 server3.properties를 사용해야 한다.
$ bin/kafka-storage.sh format \
-t $KAFKA_CLUSTER_ID \
-c config/server3.properties \
--no-initial-controllers
3. kafka 노드 3대 전부 실행하기
로그 확인을 쉽게 하기 위해 EC2 창을 각각 띄워서 포그라운드로 kafka 노드를 실행시키자.
# kafka 노드 3대 실행하기
$ bin/kafka-server-start.sh config/server.properties
$ bin/kafka-server-start.sh config/server2.properties
$ bin/kafka-server-start.sh config/server3.properties
kafka 노드 3대가 전부 잘 실행됐는 지 확인하기 위해 EC2 창을 새로 띄워서 아래 명령어를 입력해보자.
# kafka 노드들의 브로커 실행 확인
$ lsof -i:9092 # 노드 1의 브로커
$ lsof -i:19092 # 노드 2의 브로커
$ lsof -i:29092 # 노드 3의 브로커
# kafka 노드들의 컨트롤러 실행 확인
$ lsof -i:9093 # 노드 1의 컨트롤러
$ lsof -i:19093 # 노드 2의 컨트롤러
$ lsof -i:29093 # 노드 3의 컨트롤러
4. 클러스터에 컨트롤러 등록하기
$ bin/kafka-metadata-quorum.sh \
--command-config config/server2.properties \
--bootstrap-server localhost:9092 \
add-controller
$ bin/kafka-metadata-quorum.sh \
--command-config config/server3.properties \
--bootstrap-server localhost:9092 \
add-controller
5. 컨트롤러끼리 잘 연동됐는 지 확인하기
$ bin/kafka-metadata-quorum.sh \
--bootstrap-server localhost:9092 describe \
--status
Kafka 서버 3대가 서로 잘 연동됐는 지 확인하기
Kafka 서버 3대가 서로 잘 연동됐는 지 확인하는 확실한 방법은, 아래와 같이 Kafka의 서버 개수만큼 토픽의 레플리케이션을 만들어보는 것이다.

토픽을 생성하면서 레플리케이션을 생성해보자.
$ bin/kafka-topics.sh --bootstrap-server localhost:9092 \
--create --topic email.send \
--partitions 1 \
--replication-factor 3
그리고 토픽의 세부 정보를 조회했을 때, Replicas와 Isr에 3개의 숫자(1, 2, 3)가 다 있다면 3개의 Kafka 서버가 정상적으로 잘 연동되고 있다는 뜻이다.
# 토픽 세부 정보 조회하기
$ bin/kafka-topics.sh --bootstrap-server localhost:9092 \
--describe --topic email.send
- PartitionCount : 해당 토픽의 파티션 수
- ReplicationFactor : 해당 토픽의 레플리케이션 수 (원본 포함)
- Partition : 파티션 번호
- Leader : 해당 토픽의 리더 파티션을 가지고 있는 노드 id
- Replicas : 해당 토픽의 파티션을 복제하기로 설정된 노드들의 id
- Isr(In-Sync Replicas) : 리더 파티션과 똑같은 상태로 복제(동기화)가 완료된 노드들의 id (복제가 안됐으면 여기서 빠진다)
팔로워 파티션에 메시지를 넣으면 어떻게 될까?
리더 파티션은 프로듀서나 컨슈머가 직접적으로 메시지를 쓰고 읽는 파티션이다. 반면에 팔로워 파티션은 프로듀서나 컨슈머가 직접적으로 메시지를 쓰고 읽지 않는다.
라고 했는데, 실제로 팔로워 파티션에는 직접 메시지를 넣을 수 없는지 확인해보자.
토픽 상세 정보를 조회해서 리더 노드의 id를 알아낸후, 팔로워 파티션에 메시지를 넣어봤다.
$ bin/kafka-console-producer.sh --bootstrap-server localhost:19092 --topic email.send
# 위 명령어 입력 후 넣을 메시지 내용 입력하고 Enter 누르기
follower-message-1
그리고 각 노드에서 메시지를 조회해봤는데.. 모든 노드에서 삽입한 메시지가 잘 조회된다.
메시지가 모든 노드에 잘 복제된 것이다. 왜 그럴까?
사실은 Kafka 프로듀서는 메시지를 보내기 전에 해당 파티션의 리더가 누구인지 확인하고, 자동으로 리더 파티션에 메시지를 전송해준다. 이게 가능한 이유는 kafka 노드들끼리 서로 연동되어 있어서, 리더 파티션을 가진 Kafka 노드가 누군지에 대한 정보를 주고 받을 수 있기 때문이다.
리더 파티션에 장애가 발생하면 어떻게 될까?
리더 파티션에 장애가 발생하면 팔로워 파티션이 리더 역할(프로듀서로부터 메시지를 받고, 컨슈머가 메시지를 처리)을 대신 수행한다.
라고 했는데, 정말 그런지 확인해보자.

1번 노드가 리더 파티션을 가지고 있다. 그럼 1번 노드에 장애가 발생했다는 걸 가정하기 위해 1번 노드를 종료시켜보자.
포그라운드에서 실행 중이던 1번 노드 서버를 Ctrl + c로 종료시키면 된다.
다른 노드의 주소로 다시 토픽 정보를 조회해보면, Leader의 값이 2로 바뀐 것을 볼 수 있다.
리더 파티션에 장애가 발생해서 팔로워 파티션이 리더 역할을 대신 수행하게끔 리더 파티션으로 승격된 것이다.

그리고 Isr 값을 보니 1번 노드가 빠져있고 2, 3번 노드만 있는 걸 확인할 수 있다. 1번 노드가 ISR에 빠졌다는 것은 1번 노드의 네트워크가 끊겼거나, 서버에 장애가 생겼거나, 아직 리더 파티션의 데이터와 동기화가 되지 않았다는 뜻이다.
메시지를 입력해보면 정상적으로 push가 된다.
그리고 죽인 1번 서버를 재기동하면, ISR에 1번이 다시 추가가 되어있고 새로 추가한 메시지도 동기화되어 누락없이 조회가 된다.

지금까지 레플리카로 Kafka 서버 3대를 운용함으로써, 특정 kafka 서버에 장애가 발생하더라도 시스템 전체가 중단되지 않고 지속적으로 서비스를 제공할 수 있다는 점을 알아봤다. 이러한 구성은 Kafka의 고가용성(시스템이 장애 상황에서도 멈추지 않고 정상적으로 서비스를 제공할 수 있는 능력)을 확보하기 위한 대표적인 방법으로, 브로커 간 복제를 통해 데이터 손실을 방지하고, 리더 파티션 장애 시에도 다른 팔로워 파티션이 자동으로 리더로 승격되며 kafka 서버가 지속적으로 운영될 수 있게 만든다.
※ Kafka 서버는 몇 대를 운용하는 게 좋을까?
kafka 서버를 1대로 운용한다고 해서 서비스를 아예 운영하지 못할 정도의 치명적인 장애가 발생하는 건 아니다.
초기 스타트업, 초기 단계 서비스, 개발/테스트 단계에서는 비용 절감이 중요하므로 1대를 추천한다.
서비스의 안정성이 중요한 중견 기업 또는 대기업은 장애 발생 시 손실이 크므로 최소 3대 이상을 추천한다.
Spring Boot에 Kafka 서버 3대를 연결해서 사용하는 방법
Producer와 Consumer의 `application.yaml` 파일에 모든 Kafka 브로커의 주소를 등록하면 된다.
이렇게 하면 특정 브로커에 장애가 발생해도, 애플리케이션은 다른 사용 가능한 브로커에 연결하여 연속적으로 메시지를 처리한다.
server:
port: 0
spring:
kafka:
bootstrap-servers:
- {Kafka 서버 IP 주소}:9092
- {Kafka 서버 IP 주소}:19092
- {Kafka 서버 IP 주소}:29092
consumer:
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
auto-offset-reset: earliest
참고 자료 & 이미지 출처
실전에서 바로 써먹는 kafka 입문
'Middleware > Kafka (메시지 브로커)' 카테고리의 다른 글
| Kafka 메시지 처리 성능 높이기 (병렬 처리) (0) | 2026.02.16 |
|---|---|
| Kafka 메시지 처리 실패 시 대처 방법 (0) | 2026.02.15 |
| Kafka의 기본 구성 (0) | 2026.02.13 |
| Kafka 기본 개념 (0) | 2026.02.13 |
