
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- @Transactional
- Dead Letter Queue
- CORS
- docker compose
- JWT
- mybatis
- JdbcTemplate
- kafka
- redis
- securitycontextholderfilter
- Routing Key
- Spring Data JPA
- 지연 로딩
- Spring
- JPA
- AWS
- 쿠버네티스
- docker
- DLQ
- 페이징
- 스프링 부트
- dockerhub
- Web
- JPQL
- 서블릿 컨테이너
- DI
- @ComponentScan
- 컨테이너
- Spring Container
- MSA
- Today
- Total
look-forest
Deadlock 본문
이번 시간에는
멀티프로세싱, 멀티스레싱 환경에서 발생할 수 있는 deadlock이란 무엇이고, 어떻게 대응할 것인지 알아보겠다.
교착 상태(deadlock)
2개 이상의 프로세스가 다른 프로세스의 작업이 끝나기만 기다리며 작업을 더 이상 진행하지 못하는 상태
deadlock 발생 조건
deadlock은 아래 4가지 조건을 모두 만족할 때 발생한다.
- Mutual Exclusion: 적어도 1개의 resource가 배타적 자원일 때
- Hold and Wait: 어떤 자원을 할당받은 상태에서 다른 자원을 기다리는 상태 (공유 자원 2개 이상 필요할 때)
- No preemption: resource를 뺏을 수 없을 때
- Circular Wait: 점유와 대기를 하는 프로세스 간의 관계가 원을 이룸
Resource-Allocation Graph

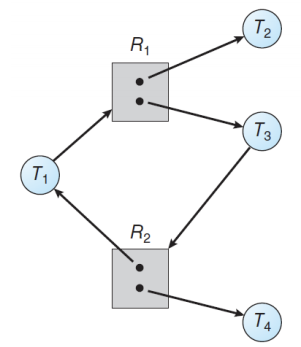
데드락을 어떻게 처리할 것인가?
- prevent
- avoid
- detect and recover
1. 예방 - 불가능
4가지 조건 중 하나만 어겨도 된다.
- Mutual Exclusion
본질적인 문제 - Hold and Wait, No Preemption
이걸 막으면 실용적이지 않음 (자원 보호 및 작업 방식 제한) - Circular Wait
리소스에 순번 부여하여 순서대로 획득 → 원형 대기 발생을 막음
but 순번을 동적으로 획득할 수 있는 경우 순번을 적용해도 교착 상태 방지가 보장되지 않음
2. 회피 - banker's algorithm
교착 상태가 발생하지 않는 수준으로 자원을 할당한다
자원의 총수와 현재 할당된 자원의 수를 기준으로 시스템을 안정 상태와 불안정 상태로 나누고, 시스템이 안정 상태를 유지하도록 자원을 할당한다.
안전한 실행 순서(safe sequence)가 존재하면 허용하고, 데드락이 있을 것 같으면 거부한다.
이를 위해서는 리소스가 어떻게 요구되는지를 알아야한다.
ex) Thread1은 Resource1, Resource2를 요구한다.
항상 safe 상태에만 머물자!
safe 상태일 때만 허용한다.
unsafe라고 무조건 데드락이 발생하는건 아니지만, 피한다

안전성 판단
새로운 reqeust(claim edge)를 반영해보고 안전할지 판단한다.
[resource type이 single instance일 때]
자원 할당 그래프에 새로운 reqeust(claim edge)를 반영해본다.
사이클이 발생하면 unsafe하다고 보고 reject. (사이클이 있다고 데드락이 발생하는 건아니지만 확실히 하기 위해..)
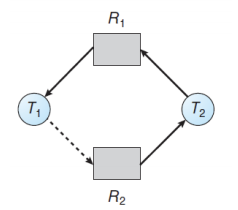
[resource type이 multiple instance일 때]
사이클 있다고 데드락인건 아니다 ▷ Banker's Algorithm 적용
시스템이 안정한가? 새로운 request를 할당해줘도 안정한가? //은행원: 이 사람에게 대출해줘도 될까?
Banker's Algorithm 과정
1) safety Algorithm: 현재 시스템 스냅샷이 safe한가?
스레드 하나하나 실행할 수 있는지 판단해보면서 모든 스레드가 실행 가능한 safe sequence를 찾는다.
① 이 스레드를 실행할 수 있는가? (need<=available)
② 실행 가능하면 실행하고 자원을 회수한다 (available+=allocated)
③ 실행 불가능하면 다른 스레드부터 살펴본다

2) Resource-Request Algorithm: 이 request를 받아들여도 되는가?
할당해줘보고 safety algorithm을 돌렸을 때 가능한지 따져본다. 불가능하면 reject.
① i번째 스레드에 request 할당 가능한가? (request<=need[i]. 스레드가 필요로 하는 것보다 요구가 더 크면 무리)
② request가 요구하는 것이 available보다 작은가? (reuqest<=available)
③ available-=request, allocation[i]+=request, need[i]-=request 인 상태해서 safety algorithm이 ture인가?
하지만 Banker's Algorithm은 자원 할당 그래프보다 복잡하고 비효율적이다.
매번 연산하는 것도 부담스럽고 자원을 낭비하는 문제가 있어 교착 상태 회피 방법은 웬만하면 사용하지 않는다.
3. detection and recovery
회피도 어렵다.. 그냥 데드락 발생하게 두자! 데드락 발생 여부를 탐지하고 회복시키자!
Deadlock Detection
[Single Instance of Each Resource Type]
wait-for graph를 유지한다. 사이클이 발생하면 데드락이 발생한 것이다.

[Several Instances of a Resource Type]
wait-for graph를 적용할 수 없다. 사이클이 있다고 데드락인게 아니기 때문 ▷ deadlock detection algorithm
deadlock detection algorithm
banker’s algorithm과 비슷한 원리이다. 다만 현재 데드락이 발생했는지 보는 것이므로, 각각 스레드마다 need[i]가 아니라 request[i]를 유지한다.
① 실행 가능 여부를 돌려본다.
② 최종적으로 finish[i]=false인 스레드들은 데드락이 발생한 것이다.
deadlock detection algorithm은 언제 호출하는가?
데드락 발생 빈도에 따라 deadlock detection algorithm을 호출한다.
스레드가 많이 관여될 수록 데드락이 발생할 가능성이 많아진다.
Recovery from Deadlock
- 데드락 일어난 걸 다 정지시킨다. (너무 부담스럽다)
- 하나씩만 죽여본다. (하나를 골라 순서대로 종료하면서 나머지 프로세스의 상태를 파악)
- 리소스를 선점해(뺏어)본다.
정지시킨 것은 rollback한다.
참고 자료 & 이미지 출처
운영체제 공룡책 강의 (주니온 님)
Operating System Concepts, 10th Ed (Silberschatz et al)
쉽게 배우는 운영체제 (조성호 님)
'Computer Science > Operating System' 카테고리의 다른 글
| 동기화 문제의 사례들 (0) | 2021.06.11 |
|---|---|
| Java의 동기화 문제 해결 (0) | 2021.06.10 |
| 임계 구역 문제 솔루션: OS, Language supported SW solution (0) | 2021.06.09 |
| 임계 구역 문제 솔루션: SW solution, HW solution (0) | 2021.06.09 |
| Critical Section Problem: 프로세스 동기화가 필요한 상황 (0) | 2021.06.09 |



