
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- DI
- 컨테이너
- 페이징
- 스프링 부트
- 서블릿 컨테이너
- @Transactional
- mybatis
- @ComponentScan
- JdbcTemplate
- Dead Letter Queue
- JPQL
- dockerhub
- Web
- CORS
- Spring Data JPA
- 지연 로딩
- docker compose
- JWT
- kafka
- Spring
- Routing Key
- redis
- DLQ
- 쿠버네티스
- JPA
- MSA
- docker
- securitycontextholderfilter
- AWS
- Spring Container
- Today
- Total
look-forest
JDBC 이해 본문
애플리케이션에서 데이터베이스에 접근할 때 사용하는 JDBC라는 기술에 대하여 알아보자.
JDBC 등장 이유
일반적으로 애플리케이션 서버에서 데이터베이스를 사용할 때는 아래 과정을 거친다.

- 커넥션 연결: 주로 TCP/IP를 사용해서 커넥션을 연결
- SQL 전달: 애플리케이션 서버는 SQL을 연결된 커넥션을 통해 DB에 전달
- 결과 응답: DB는 전달된 SQL을 수행하고 그 결과를 응답. 애플리케이션 서버는 응답 결과를 활용
문제는,
각각의 데이터베이스마다 커넥션을 연결하는 방법, SQL을 전달하는 방법, 그리고 결과를 응답 받는 방법이 모두 다르다는 것이다.
-> 데이터베이스를 변경하면 애플리케이션 서버에 개발된 DB 사용 코드도 함께 변경해야 하며, 각각 학습해야 한다.
이런 문제를 해결하기 위해 JDBC라는 자바 표준이 등장했다.
JDBC 표준 인터페이스
JDBC(Java Database Connectivity) : Java에서 데이터베이스에 접속할 수 있도록 하는 자바 API (표준 인터페이스)
대표적으로 다음 3가지 기능을 표준 인터페이스로 정의해서 제공
- java.sql.Connection : 연결
- java.sql.Statement : SQL을 담은 내용
- java.sql.ResultSet : SQL 요청 응답
이 JDBC 인터페이스를 각각의 DB 벤더에서 자사 DB에 맞도록 구현해 라이브러리로 제공하는데, 이것을 JDBC 드라이버라 한다

JDBC의 등장으로, 데이터베이스를 다른 종류의 데이터베이스로 변경하면 애플리케이션 서버의 데이터베이스 사용 코드도 함께 변경해야하는 문제가 해결되었다.
애플리케이션 로직은 이제 JDBC 표준 인터페이스에만 의존한다. 따라서 데이터베이스를 다른 종류의 데이터베이스로 변경하고 싶으면 JDBC 구현 라이브러리만 변경하면 된다.
참고 - 표준화의 한계
각각의 데이터베이스마다 SQL, 데이터타입 등의 일부 사용법 다르다. 결국 데이터베이스를 변경하면 JDBC 코드는 변경하지 않아도 되지만 SQL은 해당 데이터베이스에 맞도록 변경해야한다.
참고로 JPA(Java Persistence API)를 사용하면 이렇게 각각의 데이터베이스마다 다른 SQL을 정의해야 하는 문제도 많은 부분 해결할 수 있다.
JDBC와 최신 데이터 접근 기술
JDBC는 사용하는 방법이 복잡하다. 그래서 최근에는 JDBC를 직접 사용하기 보다는 JDBC를 편리하게 사용하는 다양한 기술이 존재한다. 대표적으로 SQL Mapper와 ORM 기술로 나눌 수 있다
SQL Mapper

- 장점 :JDBC를 편리하게 사용
- SQL 응답 결과를 객체로 편리하게 변환
- JDBC의 반복 코드 제거 - 단점 : 개발자가 SQL을 직접 작성해야 함
- 대표 기술 : 스프링 JdbcTemplate, MyBatis
ORM 기술
ORM은 객체를 관계형 데이터베이스 테이블과 매핑해주는 기술이다.

- 장점 : 개발자는 반복적인 SQL을 직접 작성하지 않고, ORM 기술이 개발자 대신에 SQL을 동적으로 만들어 실행
- > 각각의 데이터베이스마다 다른 SQL을 사용하는 문제도 중간에서 해결해줌 - 단점 : 깊이 있는 학습이 필요하다.
- 대표 기술: JPA(ORM 표준 인터페이스), 하이버네이트/이클립스링크 (구현기술)
이런 기술들도 내부에서는 모두 JDBC를 사용한다.
따라서 JDBC를 직접 사용하지는 않더라도, JDBC가 어떻게 동작하는지 기본 원리를 알아두어야 한다.
그래야 해당 기술들을 더 깊이있게 이해할 수 있고, 무엇보다 문제가 발생했을 때 근본적인 문제를 찾아서 해결할 수 있다. JDBC는 자바 개발자라면 꼭 알아두어야 하는 필수 기본 기술이다.
JDBC 연결
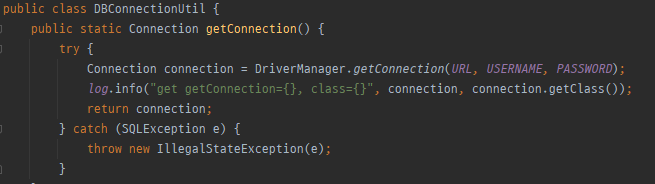
JDBC는 java.sql.Connection 표준 커넥션 인터페이스를 정의한다.
DataSource는 DB 커넥션을 얻고, SQL을 날려주는 IF이고, 구현체로 DriverManager와 ConnectionPool이 있다.
Spring은 build.gradle의 dependencies에 의존성을 추가해주면, application.properties에 있는 속성 값을 보고 DataSource객체를 만든다. 생성 당시에는 속성 값이 틀려도 모르지만, 사용 시점에 속성 값이 틀리면 커넥션을 못 만들어 에러를 낸다.
JDBC가 제공하는 DriverManager는 라이브러리에 등록된 DB 드라이버들을 관리하고, 커넥션을 획득하는 기능을 제공한다.
DriverManager 커넥션 요청 흐름
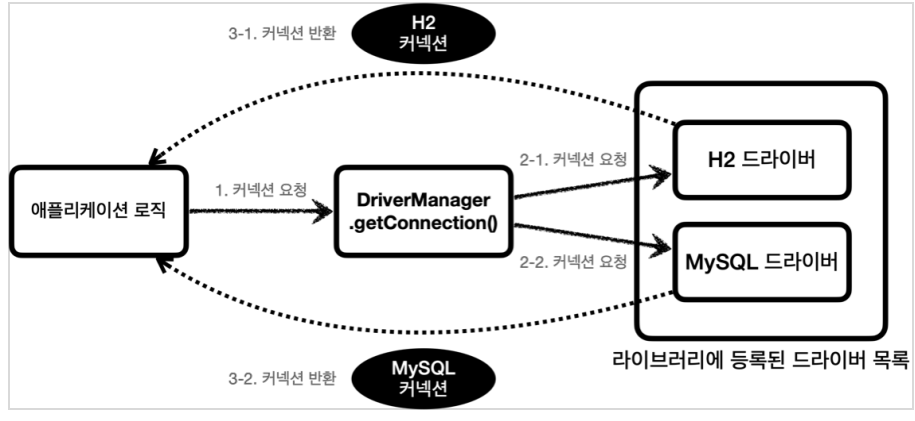
- 애플리케이션 로직에서 커넥션이 필요하면 DriverManager.getConnection() 을 호출한다.
- DriverManager 는 라이브러리에 등록된 드라이버 목록을 자동으로 인식한다.
이 드라이버들에게 순서대로 URL, 이름, 비밀번호 등 정보를 넘겨서 커넥션을 획득할 수 있는지 확인한다.
여기서 각각의 드라이버는 URL 정보를 체크해서 본인이 처리할 수 있는 요청인지 확인한다. 예를 들어 URL이 jdbc:h2 로 시작하면 h2 데이터베이스에 접근하기 위한 규칙이다. 따라서 H2 드라이버는 본인이 처리할 수 있으므로 실제 데이터베이스에 연결해서 커넥션을 획득하고 이 커넥션을 클라이언트에 반환한다. 반면에 URL이 jdbc:h2 로 시작했는데 MySQL 드라이버가 먼저 실행되면 처리할 수 없다는 결과를 반환하게 되고, 다음 드라이버에게 순서가 넘어간다 - 이렇게 찾은 커넥션 구현체가 클라이언트에 반환된다.
순수 JDBC를 이용한 개발
리소스 정리는 꼭! 해주어야 한다. 따라서 예외가 발생하든, 하지 않든 항상 수행되어야 하므로 finally 구문에 주의해서 작성해야한다. 만약 이 부분을 놓치게 되면 커넥션이 끊어지지 않고 계속 유지되는 문제가 발생할 수 있다. 이런 것을 리소스 누수라고 하는데, 결과적으로 커넥션 부족으로 장애가 발생할 수 있다
PreparedStatement 는 Statement 의 자식 타입인데, ? 를 통한 파라미터 바인딩을 가능하게 해준다.
참고로 SQL Injection 공격을 예방하려면 PreparedStatement 를 통한 파라미터 바인딩 방식을 사용해야 한다.
ResultSet 은 보통 select 쿼리의 결과가 순서대로 들어가는 데이터 구조이다. 내부에 있는 커서( cursor )를 이동해서 다음 데이터를 조회할 수 있다. rs.next() 를 호출하면 커서가 다음으로 이동한다. 참고로 최초의 커서는 데이터를 가리키고 있지 않기 때문에 rs.next() 를 최초 한번은 호출해야 데이터를 조회할 수 있다


참고 자료 & 이미지 출처
스프링 DB 1편 (김영한 님)
'Spring > Spring 데이터 접근 - 핵심 원리' 카테고리의 다른 글
| 스프링과 문제 해결 - 예외 처리, 반복 (0) | 2024.08.16 |
|---|---|
| 자바 예외 이해 (0) | 2024.08.15 |
| 스프링과 문제 해결 - 트랜잭션 (0) | 2024.08.13 |
| 트랜잭션 이해 (0) | 2024.08.12 |
| 커넥션풀과 데이터소스 이해 (0) | 2024.08.12 |


