
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- JWT
- docker
- 스프링 부트
- 쿠버네티스
- Spring
- 컨테이너
- MSA
- JPQL
- 지연 로딩
- AWS
- kafka
- dockerhub
- 서블릿 컨테이너
- @ComponentScan
- Spring Data JPA
- docker compose
- CORS
- DI
- Routing Key
- @Transactional
- Dead Letter Queue
- securitycontextholderfilter
- DLQ
- redis
- Spring Container
- 페이징
- Web
- JPA
- mybatis
- JdbcTemplate
- Today
- Total
look-forest
Redis (feat.조회 수) 본문
조회 수 기능 구현을 통해 대규모 시스템에서 Redis를 어떻게 활용하는지 알아보자.
조회수 어뷰징 방지 정책은 다음과 같다.
- 각 사용자는 게시글 1개 당 10분에 1번 조회 수 집계
조회수 설계
조회 수는 게시글 수나 좋아요 수와는 달리, 다른 데이터의 개수로 파생되는 것이 아니다.
좋아요 수에 비해 데이터 일관성이 덜 중요하고, 쓰기 트래픽이 비교적 많다.(게시글 조회만만 해도 트래픽이 증가하므로)
따라서 디스크 접근 비용과 트랜잭션 관리 비용을 감수할 필요가 없다.
따라서, In-memory Database를 사용해 볼 수 있고, 많이 사용되는 Redis를 사용하자.
인기글 선정 시 필요하므로, 자체적인 백업 시스템도 간단히 구축해본다.(Redis에 저장된 데이터를 MySQL에 직접 백업)
Redis
- In-memory Database -> 고성능
- NoSQL Database -> 키-값 저장소
- 다양한 자료구조 지원(String, List, Set, Sorted Set, Hash 등)
- TTL(Time To Live) 지원 -> Lock으로 활용 가능
- Single Thread에서 순차 처리 -> 동시성 문제를 해결하는데 유리
Redis의 싱글 스레드는 여러 요청이 동시에 들어와도 순차적으로 처리해 동시성 이슈 없이 안전하게 데이터를 갱신하거나 락을 확보할 수 있게 해준다. - 데이터 백업 지원 -> 디스크에 저장하는 방법 제공(AOF, RDB)
- AOF(Append Only File): 수행된 명령어를 로그 파일에 기록하고, 데이터 복구를 위해 로그를 재실행
- RDB(SnapShot): 저장된 데이터를 주기적으로 파일에 저장
- 약간의 데이터 유실은 허용한다는 관점이기 때문에, 실시간으로 모든 데이터를 백업할 필요는 없다
- 시간 단위 백업(배치) or 개수 단위 백업
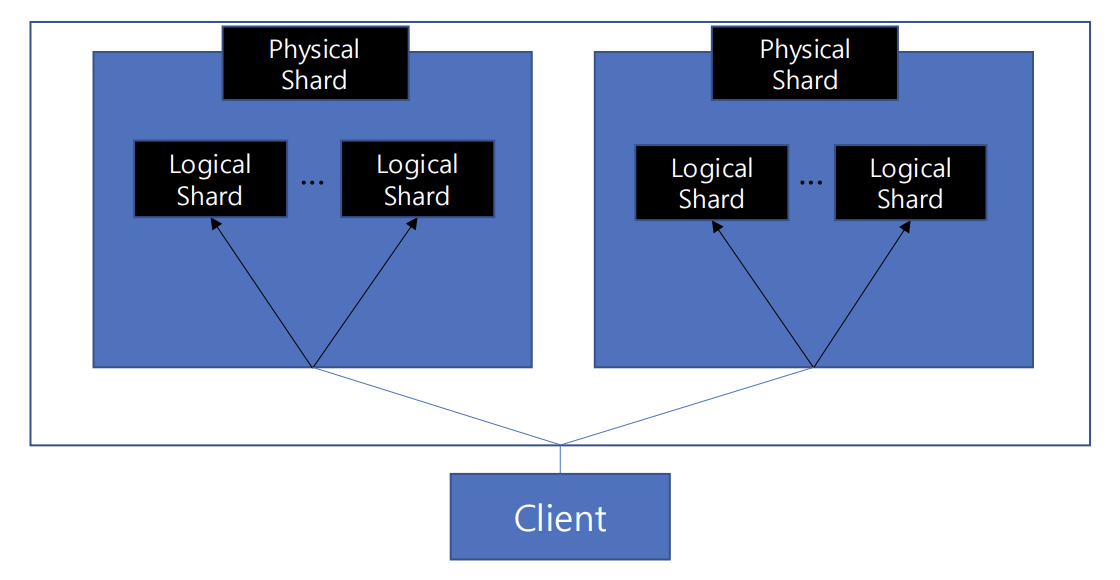
- Redis Cluster -> 확장성, 부하 분산, 고가용성을 위한 분산 시스템 구성 방법 제공
- 수평 확장
- 데이터 복제 기능 제공(고가용성)
- 샤딩 지원: key의 hash 값으로 slot(Logical Shard)을 구하고, slot으로 shard(Physical Shard) 선택
1. slot = hash_function(key)
2. shard = select_shard(slot)

구현
Redis용 Repository와 DB 백업용 Repository를 만든다.
@Repository
@RequiredArgsConstructor
public class ArticleViewCountRepository {
private final StringRedisTemplate redisTemplate; //기본적으로 만들어줌. 이걸 통해 redis와 통신
// view::article::{article_id}::view_count
private static final String KEY_FORMAT = "view::article::%s::view_count";
public Long read(Long articleId) {
String result = redisTemplate.opsForValue().get(generateKey(articleId));
return result == null ? 0L : Long.valueOf(result);
}
public Long increase(Long articleId) {
return redisTemplate.opsForValue().increment(generateKey(articleId));
}
private String generateKey(Long articleId) {
return KEY_FORMAT.formatted(articleId);
}
}@Repository
public interface ArticleViewCountBackUpRepository extends JpaRepository<ArticleViewCount, Long> {
@Query(
value = "update article_view_count set view_count = :viewCount " +
"where article_id = :articleId and view_count < :viewCount", //동시 요청이 많아서 업데이터 쿼리 꼬이는 경우 방어
nativeQuery = true
)
@Modifying
int updateViewCount(@Param("articleId") Long articleId, @Param("viewCount") Long viewCount);
}
서비스에서는 Redis를 통해서만 조회수 조회, update 한다. (cache aside x)
그리고 100개 단위로 DB에 백업한다.
@Service
@RequiredArgsConstructor
public class ArticleViewService {
private final ArticleViewCountRepository articleViewCountRepository;
private final ArticleViewCountBackUpProcessor articleViewCountBackUpProcessor;
private static final int BACK_UP_BATCH_SIZE = 100;
public Long increase(Long articleId) {
Long count = articleViewCountRepository.increase(articleId);
if (count % BACK_UP_BATCH_SIZE == 0) {
articleViewCountBackUpProcessor.backUp(articleId, count);
}
return count;
}
public Long count(Long articleId) {
return articleViewCountRepository.read(articleId);
}
}
@Component
@RequiredArgsConstructor
public class ArticleViewCountBackUpProcessor {
private final ArticleViewCountBackUpRepository articleViewCountBackUpRepository;
@Transactional
public void backUp(Long articleId, Long viewCount) {
int result = articleViewCountBackUpRepository.updateViewCount(articleId, viewCount);
//0이면 백업 데이터가 없거나, 작은 수로 업데이트 시도한 경우
if (result == 0) {
articleViewCountBackUpRepository.findById(articleId)
.ifPresentOrElse(ignore -> {},
//없을 경우 신규 저장
() -> articleViewCountBackUpRepository.save(ArticleViewCount.init(articleId, viewCount))
);
}
}
}
조회수 어뷰징 방지 정책 설계
어뷰저는 특정 게시글을 여러 번 조회해서 데이터를 조작할 수 있다.
조회수 기반으로 인기글이 산정되는 경우, 올바르지 않은 어뷰징 데이터로 인기글이 선정될 수 있기 때문에 방지가 필요하다.
10분 동안 100번 조회하더라도 조회수는 1회만 집계되어야 한다.
어뷰징을 방지하기 위한 조회 여부 식별
어뷰징을 방지하기 위한 조회 여부는 어떻게 식별할 수 있을까?
로그인 사용자라면 Id로 식별할 수 있고,
비로그인 사용자라면 IP, User-Agent, 브라우저 쿠키, 토큰 등 다양한 방법으로 식별할 수 있다.
여기서는 정책을 간소화하기 위해 로그인 사용자에 대해서만 식별하겠다.
조회 여부 저장
그렇다면, 각 사용자가 최근 10분 내에 게시글을 조회했었다는 사실을 어떻게 알 수 있을까?
스프링부트는 무상태(stateless) 애플리케이션이다. 하지만 우리는 이러한 상태를 관리해야 한다.
상태 저장소로 데이터베이스를 활용하면 어떨까? 조회 내역을 저장하고 매번 확인하는 것이다.
아래 이유로 데이터베이스가 아닌 Redis를 사용하는 것이 좋다.
- 게시글 조회 트래픽은 많을 수 있다. 그래서 조회수 집계는 성능을 위해 MySQL 대신 Redis를 선정한 것이다.
여기서 다시 MySQL을 사용한다면, Redis를 선정한 의미가 없다. - 동시성 문제가 발생할 수 있다. 조회 수 동시 요청이 들어온다면,
Mysql에서는 락을 점유하는 상황이 필요할 수 있다.
하지만 Redis는 Single Thread로 동작하므로, 하나의 명령어는 원자적으로 처리된다. 동시성 문제를 다루는데 유리하다. - MySQL은 데이터 자동 삭제를 지원하지 않는다.
게시글이 삭제되거나 더 이상 갱신될 일이 없다면, 직접 삭제를 위한 배치 등의 시스템을 구축해야 한다.
반면 Redis는 TTL을 지원해서, 별도 삭제 시스템을 구축하지 않아도 자동으로 데이터가 삭제된다.
설계
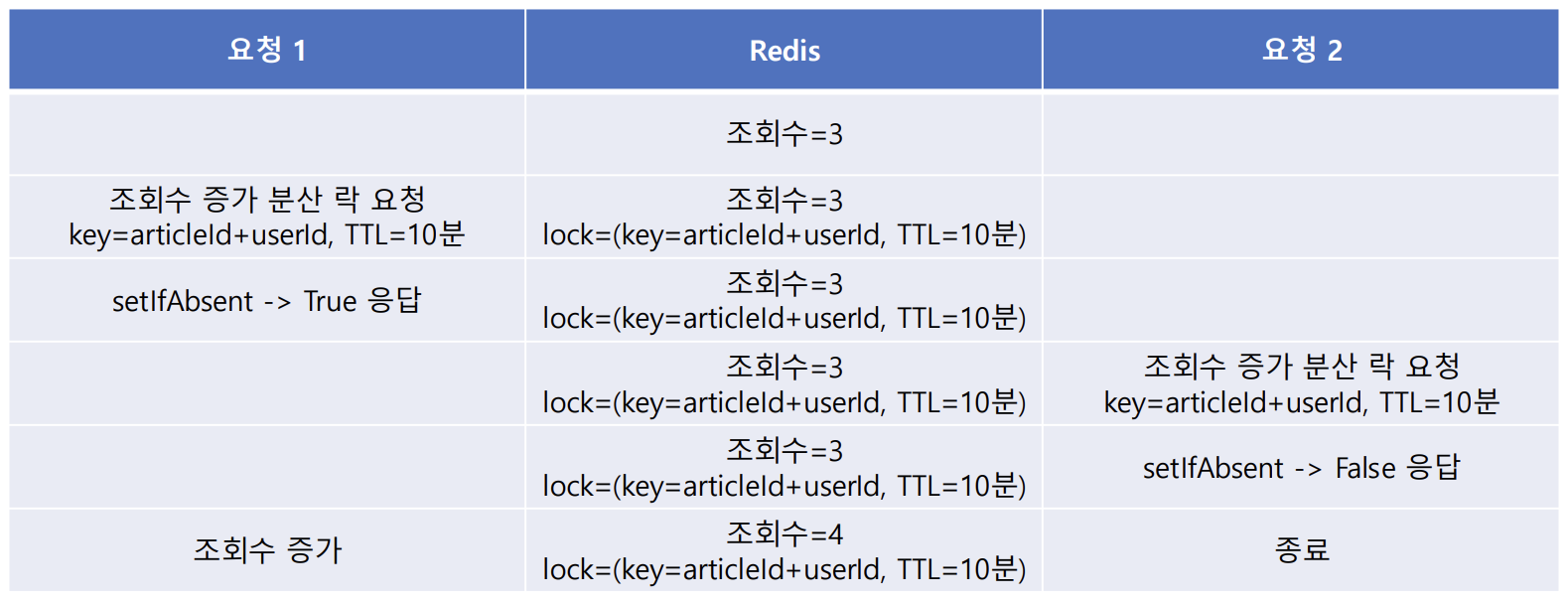
따라서, Redis를 아래 프로세스로 활용한다.
- 조회수 증가 요청이 오면, Redis에 TTL=10분으로 데이터를 저장한다
- 게시글 조회는 사용자 단위로 식별되므로, key=(articleId+userId)
- 이미 저장된 데이터가 있으면 저장에 실패하는 명령어를 사용
-> setIfAbsent: 데이터가 없을 때에만 저장. 성공하면 True, 실패하면 False 반환
- 데이터 저장 성공 여부에 따라 조회 수 증가
- 성공 했으면, 조회 내역이 없었음을 의미 -> 조회수 증가
- 실패 했으면, 조회 내역이 있었음을 의미 -> 조회수 증가 X
이러한 과정은, 조회수 증가에 대해서 일종의 Lock을 획득한다고 볼 수 있다.
우리 시스템은 확장성이 고려된 분산 시스템이고, 분산 시스템에서 락을 획득하는 것을, 분산 락(Distributed Lock)이라고 한다.
조회수 서비스의 여러 서버 애플리케이션들은 사용자의 게시글 조회수 증가에 대해서 10분 간 분산 락을 획득한다고 볼 수 있다.
구현
조회 이력이 있으면 데이터를 저장할 수 있도록 하고(set if absent), 10분의 TTL을 가진 데이터를 삽입해 일종의 Lock을 건다.
TTL은 Lock을 자동으로 해지해준다.
@Repository
@RequiredArgsConstructor
public class ArticleViewDistributedLockRepository {
private final StringRedisTemplate redisTemplate;
// view::article::{article_id}::user::{user_id}::lock
private static final String KEY_FORMAT = "view::article::{article_id}::user::{user_id}::lock";
public boolean lock(Long articleId, Long userId, Duration ttl) {
String key = generateKey(articleId, userId);
return redisTemplate.opsForValue().setIfAbsent(key, "", ttl);
}
private String generateKey(Long articleId, Long userId) {
return KEY_FORMAT.formatted(articleId, userId);
}
}
@Service
@RequiredArgsConstructor
public class ArticleViewService {
private final ArticleViewCountRepository articleViewCountRepository;
private final ArticleViewDistributedLockRepository articleViewDistributedLockRepository;
private final ArticleViewCountBackUpProcessor articleViewCountBackUpProcessor;
private static final int BACK_UP_BATCH_SIZE = 100;
private static final Duration TTL = Duration.ofMinutes(10);
public Long increase(Long articleId, Long userId) {
if (!articleViewDistributedLockRepository.lock(articleId, userId, TTL)) {
return articleViewCountRepository.read(articleId);
}
Long count = articleViewCountRepository.increase(articleId);
if (count % BACK_UP_BATCH_SIZE == 0) {
articleViewCountBackUpProcessor.backUp(articleId, count);
}
return count;
}
public Long count(Long articleId) {
return articleViewCountRepository.read(articleId);
}
}
테스트를 돌려보면, 1만 번 조회해도 조회수는 1로 나온다.
참고 자료 & 이미지 출처
스프링부트로 직접 만들면서 배우는 대규모 시스템 설계 - 게시판
'Architecture > 대규모 시스템 설계' 카테고리의 다른 글
| 동시성 문제 (feat.좋아요 수) (0) | 2026.02.08 |
|---|---|
| 계층형 구조와 페이징(feat.댓글) (0) | 2026.01.23 |
| 대용량 데이터의 조회(feat.페이징,인덱스) (0) | 2026.01.03 |
| Primary key 생성 전략 (0) | 2026.01.03 |
| Distributed Database (0) | 2026.01.02 |